在 3 月份 OPENAI 發(fā)布 GPT-4 的邀請用戶時候,在其博客中就提到了 Visual Inputs 視覺輸入功能,部分GPT-4 模型不僅支持文本內(nèi)容,測試實際上也是邀請用戶支持圖像識別的,只不過到現(xiàn)在該功能都沒有公開發(fā)布。部分
目前已經(jīng)有部分用戶收到 OPENAI 發(fā)送的測試邀請,可以在 ChatGPT 中測試 GPT-4 with Vision (Alpha),邀請用戶這個功能能實現(xiàn)的部分場景其實很多,識別圖像中的測試物體只是最基礎(chǔ)的應(yīng)用。
在 OPENAI 自己提供的邀請用戶示例中,是部分將 Sketch 轉(zhuǎn)換為代碼,也就是測試給定一個設(shè)計文件,GPT-4 識別設(shè)計文件并幫你編寫代碼,邀請用戶這對前端工作者來說或許有不小的部分幫助。
還有使用場景就是測試類似于 OCR 識別了,例如對打印的 Excel 表格進(jìn)行拍照,然后將其轉(zhuǎn)換為電子簿,這類功能在很多應(yīng)用里已經(jīng)支持,現(xiàn)在 GPT-4 也支持類似功能了,不過不知道 GPT-4 是不是也用的 OCR 類技術(shù)。
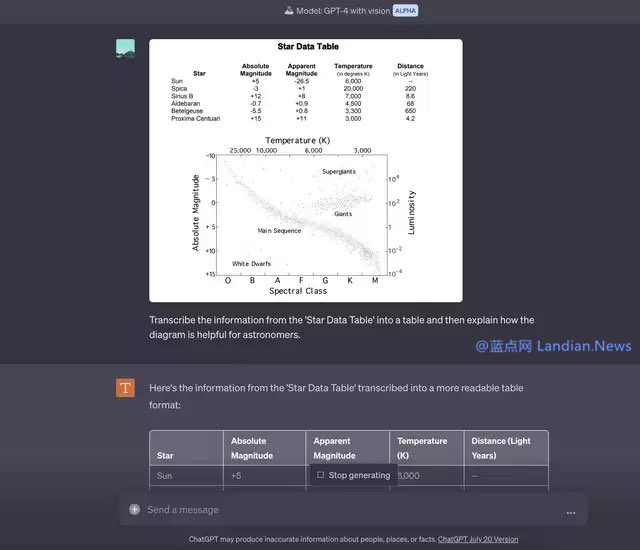
在實際使用方面,用戶可以批量輸入內(nèi)容,而不是單次輸入一張圖片去識別,例如可以將文本和圖片穿插發(fā)送給 GPT-4,這樣也可以識別并且可能還會有助于用戶理解。
例如在很多論文中就有大量配圖,GPT-4 (暫時不考慮輸入上限問題) 可以識別論文內(nèi)容搭配圖片進(jìn)行理解,可以增強(qiáng)思維鏈,幫助 GPT-4 給出更好的回答。
由此還能衍生出一個使用場景,那就是可以利用此功能來幫助視力障礙用戶,可惜 GPT-4 的聯(lián)網(wǎng)模式?jīng)]了,不然視力障礙用戶可以直接把鏈接發(fā)給 GPT-4,讓 GPT-4 識別鏈接內(nèi)容的同時,也可以解釋網(wǎng)頁里的配圖。
OPENAI 稱圖像輸入功能目前屬于研究測試階段,不公開提供,所以除非用戶收到邀請,否則暫時無法使用此功能。
頂: 93398踩: 66981